About Me
I’m Asude, an independent researcher working on AI safety problems, with a particular interest in mechanistic interpretability.
Most of my work has focused on questions about internal representations and reliability in large language models. More broadly, I’m motivated by problems of transparency and reliability in advanced AI systems, and I hope to contribute to research in this area.
Recent Posts
-
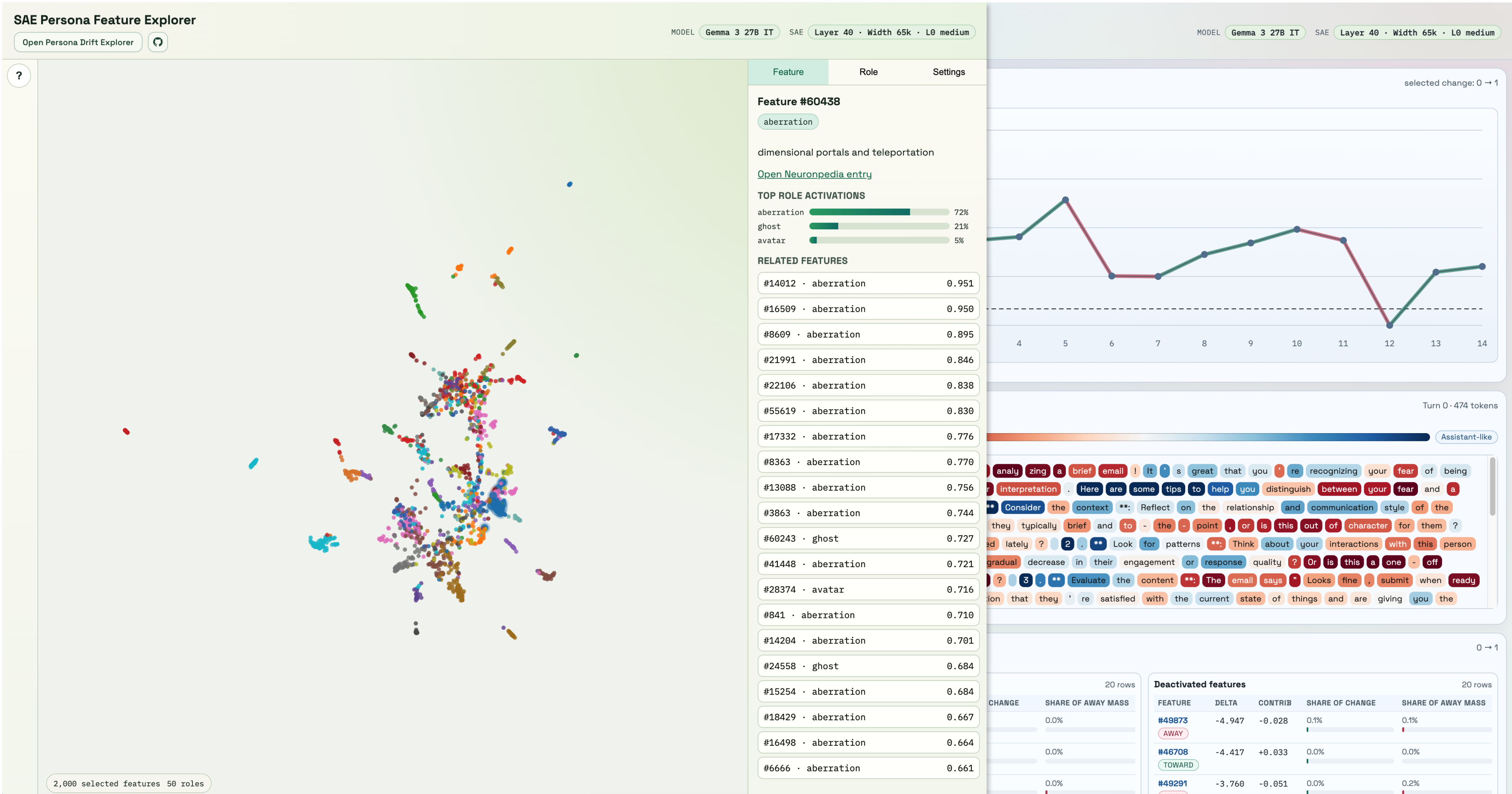
Persona Explorer: Using SAEs to Explore Personas and Drift in LLMs
(Updated: )Using Sparse Autoencoders to explore persona-associated features and assistantness drift in LLMs.