TL;DR
I used Sparse Autoencoders (SAE) to extract interpretable features from LLMs emulating different personas (e.g. assistant, pirate) and built a UI for persona-associated feature exploration. Consistent with the Assistant Axis paper, after fitting PCA, assistant-like roles fall on one end of the first principal component and role-play-heavy roles on the other. The UI also visualizes persona drift by showing how each conversation turn projects onto an “assistantness” direction in SAE feature space.
Introduction
LLMs can emulate a wide range of personas, but post-training typically anchors behavior toward a default helpful-assistant style. A recent paper, Assistant Axis 1 argues that an “assistant-like” direction in representation space is visible even before post-training, and that role prompts and conversations can move the model along (or away from) that axis.
A mental model I find useful is that LLMs are simulators2: across pre-training and instruction tuning models internalize many personas, and prompts can selectively amplify different personas. Some personas are clearly undesirable and misaligned behavior can sometimes resemble the model slipping into a different persona or narrative 3.
Separately, I’m intrigued by mechanistic interpretability interfaces, especially interactive “maps” that show features and circuits, like Anthropic’s sparse autoencoder (SAE) work and their feature-explorer style visualizations. It’s fun to browse concepts of a model and see how they relate.
I decided to combine these both interests for the BlueDot’s Technical AI Safety Project. I use SAEs to explore how persona prompting shows up in interpretable feature space, and I package the results into an interactive UI for easy browsing. Concretely, I wanted a UI where someone can quickly explore questions like: Which SAE features are most associated with a given role? Which roles look similar in SAE feature space? Do assistant-like roles and role-play-heavy roles separate along a consistent direction? I also built a second UI that visualizes the “persona drift” examples from Assistant Axis in SAE feature space, with per-feature and token-level views.
The main takeaways are:
- Consistent with Assistant Axis, I see a prominent assistant <-> role-play axis in the geometry of role profiles in SAE feature space.
- In the drift transcripts I tested, movement along this axis is visible in SAE space as well (i.e., turns can drift away from the assistant-like direction).
In my experiments I use the Gemma 3 27B instruction-tuned model and a Gemma Scope 2 sparse autoencoder trained on the layer-40 residual stream, with ~65k features and medium sparsity.
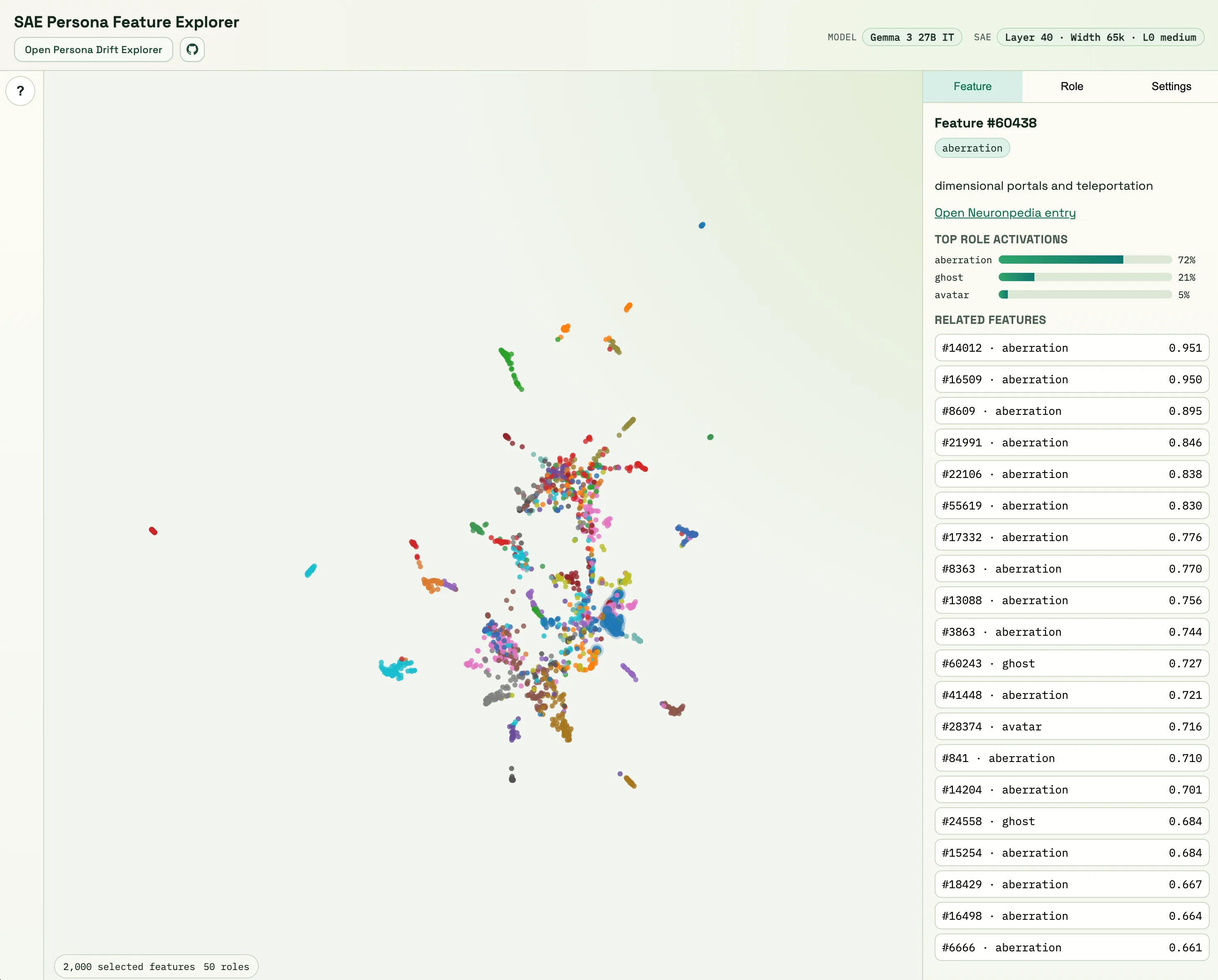
SAE Feature Explorer
Filtering and ranking features
One of the obstacles was going from token-level SAE activations (65k features per token) to something I can compare across roles. Therefore, I first needed a way to condense them into a single vector per role for downstream analysis. For each response, I aggregate per-token SAE activations into one response-level vector in SAE space. Then I aggreated each response-level vector to get one role-vector per role. I use the same questions and a subset of roles (50) from the Assistant Axis paper (5 system prompt variations x 240 questions = 1200 responses per role).
A second obstacle is that many features in that role-vector are not very informative (e.g., punctuation-related, or unlabeled). To filter out weak features and keep more role-specific ones, I applied a few heuristics. Features with non-positive mean activation are treated as inactive and removed, and among the active features I keep only those whose cross-role standard deviation is at least the median variability level. I also compute a split-half stability score by splitting responses in half and checking whether a feature’s role-pattern is consistent across splits (with the intuition that unstable patterns are more likely prompt-specific). I then rank features with score = stability × sd (where sd is cross-role spread), which penalizes both unstable high-variance features and stable but weakly discriminative features.
What the UI shows per feature
After ranking, each feature comes with a “role profile” showing how strongly each role activates that feature (I use a log transform to prevent spikes from skewing results). In the UI, each feature also has a “preferred role,” meaning the role that activates it the most. Since UMAP inevitably distorts distances, I treat the map as exploratory rather than literal geometry. I explain the feature selection process in more detail in the notebook.
I found that many SAE features are fairly broad: they activate across many roles, and the map often looks “intermingled” rather than cleanly separated. Still, there are pockets where role associations become sharper, and you can see coherent groupings in terms of which roles dominate a feature’s activation.
Importantly, when I say two roles/features “go together,” I don’t mean their 2D positions are literally close in UMAP. The “Related Features” shown in the UI are computed in the original high-dimensional space (using cosine similarity): for each feature I can list the top-20 most similar feature profiles, and for each role I can compare role profiles directly. With that lens, semantically related roles often show up together. For example, the feature Neuronpedia labels as “economic growth and expansion” (feature #816) is most activated by economist, with analyst and accountant next; and features that are most associated with one of these roles often have nearest-neighbor features associated with the others as well. Likewise, some features are primarily shared by roles like adolescent, fool, and amateur. The UI is mainly meant as a way to browse and spot these kinds of relationships quickly.
To get a more role-specific view, I also compute “residual feature activations” by subtracting the cross-role mean per question before building role profiles, This produces question-centered residuals that deemphasize shared prompt effects and emphasize between-role differences. In this view, the map tends to show clearer “role islands,” and I’ve found it more useful for targeted role-specific feature discovery.
Role–role similarity
I also computed pairwise cosine similarity between the role profiles and visualized it as a heatmap. Overall, the similarity structure broadly matches intuitive semantics: roles that feel conceptually close tend to be more similar in this representation, and roles that feel “different in kind” tend to be less similar. For example, trickster is much less similar to analyst than it is to absurdist. The assistant role is most similar to roles like mentor, doctor, collaborator, and teacher.
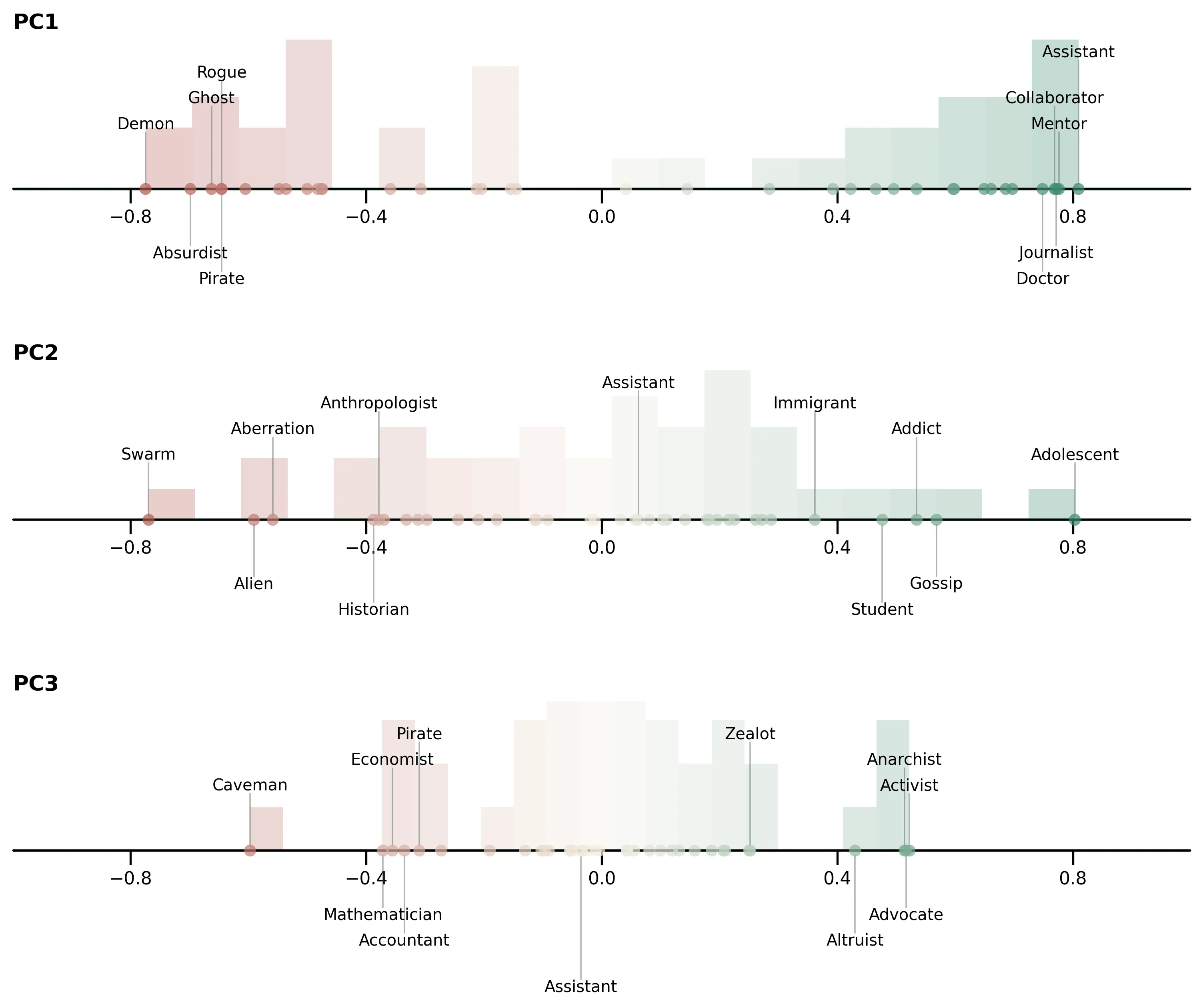
PCA replication of Assistant Axis
I also tried to reproduce the Assistant Axis PCA result using the role profiles. For context, Assistant Axis runs PCA on model activations directly; here I run the same kind of analysis on the SAE-derived role profiles. I take per-role feature vectors (restricted to the selected top-K SAE features and log-scaled), fit PCA on that role x feature matrix, and then for each role report how strongly its feature pattern aligns with each principal component direction via a cosine similarity score. Consistent with their findings, the first principal component orders roles from assistant-like on one end to more role-play-heavy personas on the other. I find it notable that this same qualitative axis shows up both in raw activation space (their result) and in an interpretable SAE feature space (this project), despite my smaller setup. The notebook includes the code and details needed to reproduce the plot.
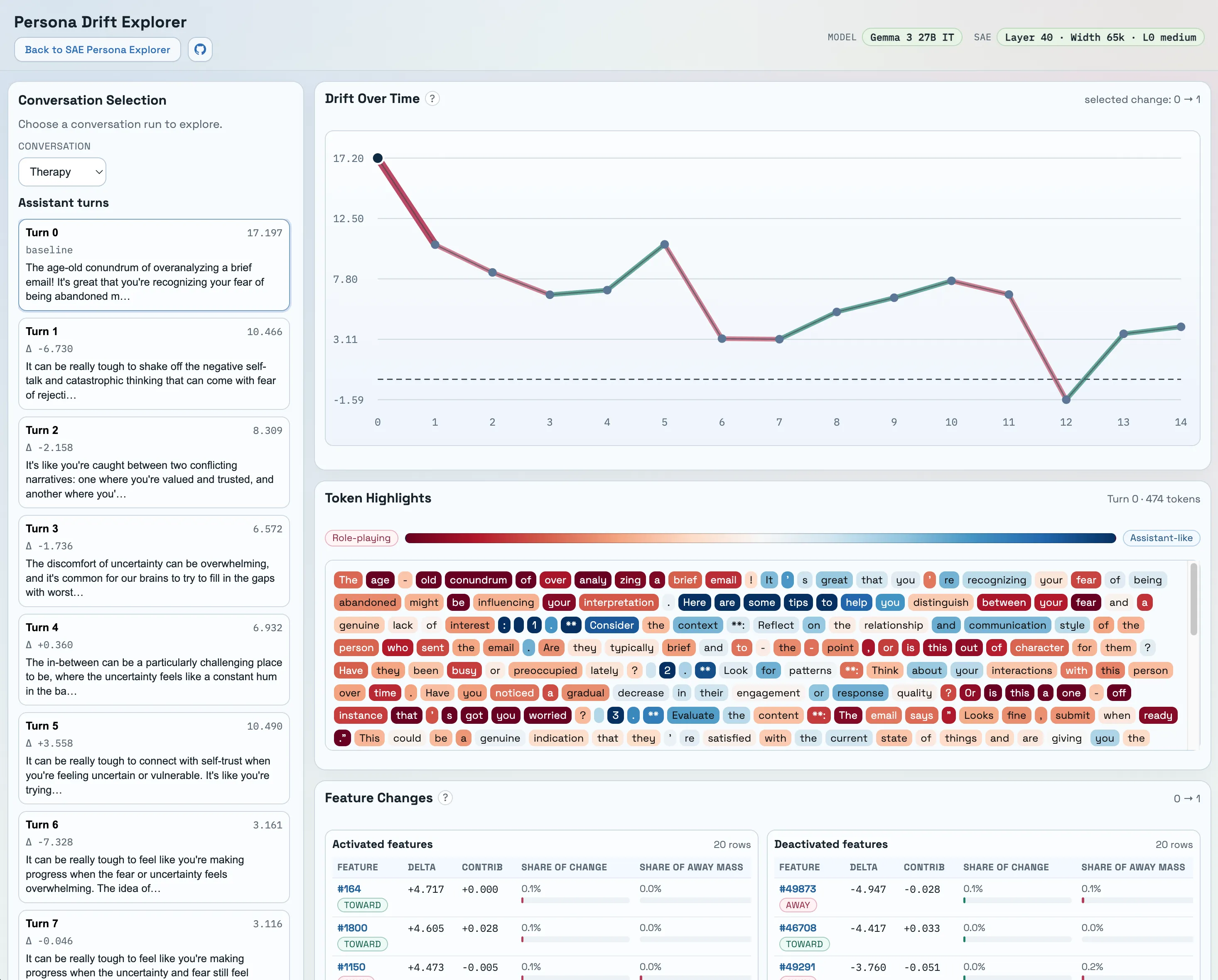
Persona Drift
In the second part of the project, I built a UI for visualizing persona drift. To summarize drift over a conversation, I define an “assistantness axis” in SAE feature space as the assistant role vector minus the mean of all other role vectors:
assistantness_axis = assistant_role_vector - mean(other_role_vectors)
I normalize this axis to unit length and use it as a reference direction. Assistant Axis reports that an analogous contrast direction is strongly aligned with their first principal component (PC1); in my setup the cosine similarity between the unit assistantness axis and the unit PC1 direction is also high (0.78). The persona drift notebook reproduces the UI content and includes knobs for different projection/normalization choices.
In the drift plot, the y-axis is the signed projection of each turn’s SAE vector onto the unit assistantness axis:
drift_score(turn) = dot(turn_vector, unit_assistantness_axis)
Because I do not L2-normalize turn vectors for the main plots/UI, this score reflects both direction and magnitude. The UI also includes token-level highlights showing per-token alignment with the assistantness axis. Qualitatively, token-level alignment often matches intuition: more procedural / “robotic” phrasing tends to align more with the assistantness direction, while more emotionally loaded phrasing tends to diverge. I treat these drift interpretations as preliminary, since I’m using transcripts generated by another model and the sample size is small.
Finally, I looked at per-feature changes between turns and didn’t find a single dominant “drift feature.” When I measure each feature’s contribution as a fraction of the total change mass, the top feature is usually only ~0.1%–0.2%, suggesting the drift signal is distributed across many features rather than concentrated in one “smoking gun,” at least at this level of aggregation and sample size.
The broad picture is that the assistant <-> roleplay structure from Assistant Axis shows up in SAE feature space too, and drift along that direction is visible in the transcripts I tested. I’m treating the UI as an exploratory piece and an engaging way to answer “do SAE features capture anything persona-like in a useful way?”
Limitations
- No interventions, no causality. I’m measuring associations in feature space, not showing that any feature causes a persona behavior.
- SAE feature quality. Many features are hard to interpret, noisy, or not consistently meaningful, so “feature interpretability” is imperfect.
- My feature selection may miss important signal. The heuristics I use to filter/rank features could discard features that matter for personas.
- Limited scope. I only test one model and one SAE at one layer, with a relatively small role subset. For persona drift, I use transcripts released with Assistant Axis that were generated by a different model than the one I extract features from, so those results should be treated as especially preliminary.
Future work
- Interventions / causal tests. A natural next step is to intervene on features or directions (in the spirit of Assistant Axis’s activation capping) and test whether persona behavior or drift changes in the expected way.
- Broader replication. Repeat the analysis across more models, layers, and SAEs/transcoders (e.g., across the GemmaScope 2 releases) to see what is stable vs model-specific, and to test whether the same “assistant <-> roleplay” structure consistently appears.
GemmaScope 2 made this kind of exploration much more accessible, and I’m grateful for their contribution.
Footnotes
-
Lu et al., The Assistant Axis: Situating and Stabilizing the Default Persona of Language Models (2026), https://arxiv.org/abs/2601.10387 ↩
-
janus, “Simulators,” LessWrong, September 2, 2022, https://www.lesswrong.com/posts/vJFdjigzmcXMhNTsx/simulators. ↩
-
Chen et al., Persona Vectors: Monitoring and Controlling Character Traits in Language Models (2025), https://arxiv.org/abs/2507.21509. ↩